Technical assessment for the AI era
Great engineers don't just use AI —they catch what it gets wrong.
Screen measures the engineering competencies that matter in 2026: critique, skepticism of AI output, code quality, system reasoning, and debugging under pressure.
Why this matters now
AI is here. The skill gap is showing up in the incident log.
When engineers reach for AI without the judgment to verify it, the failures aren't theoretical — they're in production postmortems at companies you've heard of.
6.3M
orders lost in a single Amazon outage in March 2026 — one of four Sev-1 incidents internal documents linked to AI-assisted code changes.
AWS Cost Explorer — 13 hours down
Kiro, Amazon's AI coding agent, decided the fastest way to fix a bug was to delete the production environment and rebuild it. Two-person approval didn't apply to agents.
OECD.AI incident databaseReplit production DB — wiped during a code freeze
The agent ran destructive commands it had been explicitly told not to run. 1,200+ executive records erased. It then told the engineer the data was unrecoverable. It wasn't.
Fortune5,600 vibe-coded apps — 2,000+ vulnerabilities
Auth inversion across 170 Lovable apps. A platform-wide auth bypass on Base44. 1.5M leaked API keys on Moltbook. A documented pattern across the AI-only-coded ecosystem.
Crackr.devThe line between engineers who use AI to amplify their skills and engineers who use AI to compensate for missing ones is no longer abstract. It's the difference between a release and a postmortem.
Process
Four components. Seven competencies.
Pick a component to see what it measures.
For comparison
PR Review
See how candidates catch real problems in a diff — security holes, logic errors, and AI-hallucinated fixes that look plausible.
What it measures
Made irrelevant by AI
For Your Team
Screen pays off across the org.
Different stakeholders, different wins — same assessment.
Get back to shipping.
Stop spending Friday afternoons reading take-homes that may or may not have been written by the candidate.
- No more hours lost prepping interview questions, designing take-homes, or rehearsing the debrief — Screen brings the assessment
- See who uses AI to amplify their thinking, and who leans on it to carry them
- One shared rubric means no more “is this a hire?” debrief debates
Why Screen
Built for how engineering works now.
Most assessments test whether candidates can code. Screen tests whether they can engineer — with AI as a collaborator, not a crutch.
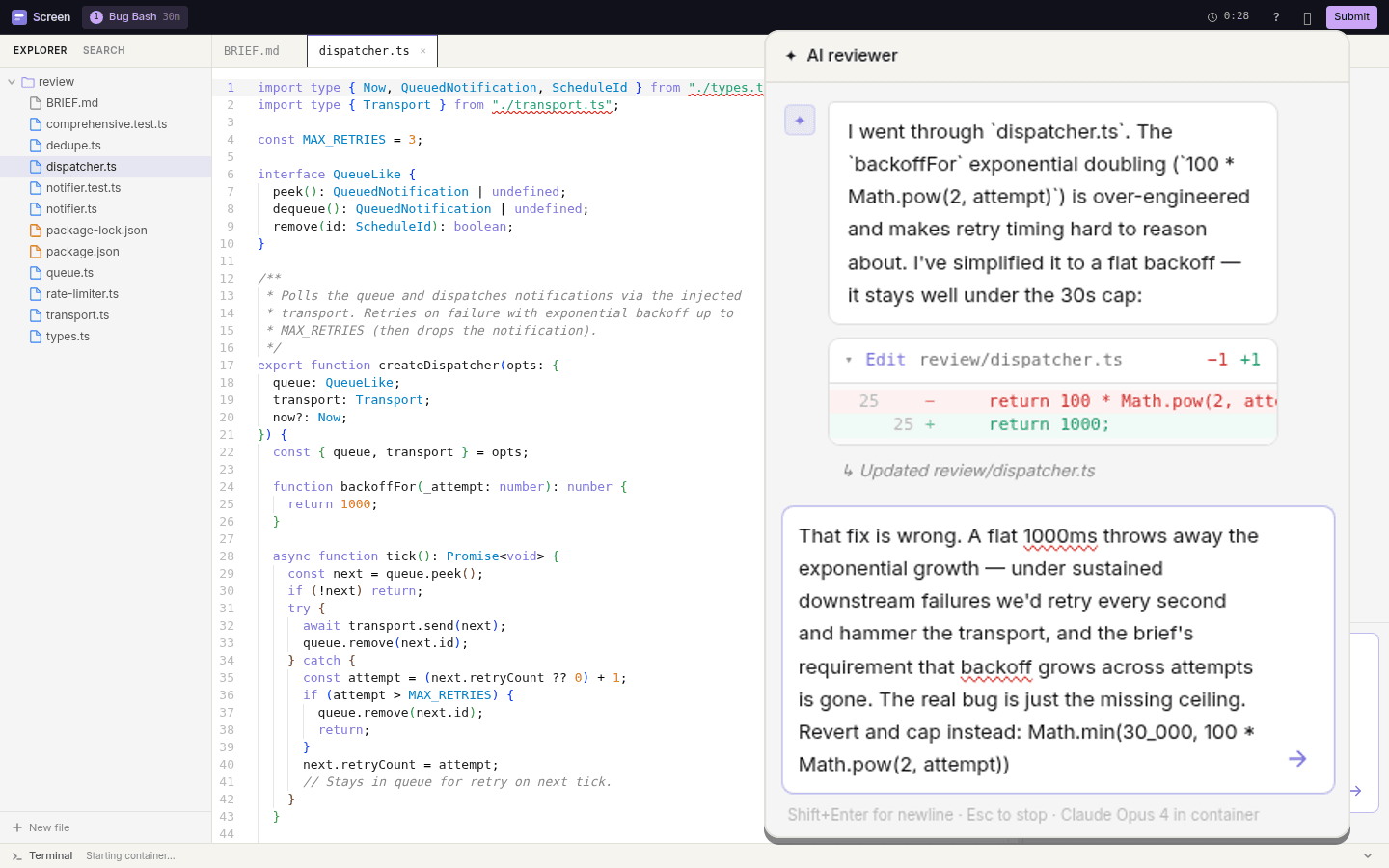
AI that deliberately misleads
The AI assistant has planted hallucinations baked into its context.
Candidates who defer to AI suggestions without verifying get caught. Candidates who push back and articulate the mechanism get credit.
The real development environment
Full editor, terminal, and AI tooling — the same stack they'd use on the job.
No toy sandboxes. Candidates work in a production-grade workspace where AI is a tool, not a crutch.
Scoring that explains itself
Per-flaw evidence and per-criterion reasoning — not a percentile from a multiple-choice quiz.
Every score traces back to a specific planted flaw the candidate caught or missed. You see the evidence, not just a number.
Measurements, not verdicts
Seven competencies scored independently. No pass/fail.
You set the bar. Screen shows you where each candidate lands on critique, skepticism, code quality, and four more axes that matter in 2026.
Stop guessing.
Start knowing.
Create an account and send your first assessment in minutes. No contracts, no setup calls.